Oracle Block
굉장히 내부적인 내용이라 공부해야지 해야지 하면서 미뤄뒀던.. Oracle Block 내용을 정리해볼까 합니다.
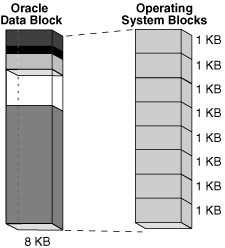
Data Block은 OS Block과는 다른 의미를 가집니다. OS Block은 OS가 read/write하는 최소 단위를, Oracle Block은 오라클 데이터베이스 I/O 최소 단위를 의미합니다. 이렇듯 아래 그림처럼 블럭의 크기또한 다르게 구성 될 수 있습니다.
그렇다면 Data Block은 어떻게 구성되어 있을까요?
크게보면 아래 두가지로 나뉘어집니다.

Data Block Overhead(Common and Variable Header/Table Directory/Row Directory)
Block 자신을 관리하기 위한 영역. 따라서 해당 영역에 user data를 저장할 수 없다.
1.1. Block Header
disk address, segment type등 Block에 대한 일반적인 정보 및 transaction관련 정보를 포함.
Block을 Update하는 모든 트랜잭션에 transaction entry가 필요하다. Oracle은 처음에 block header에 transaction entries를 위한 공간을 예약한다. transactional changes를 지원하는 segment에 할당된 data blocks에서는, header space가 부족할 때 free space에 transaction entries를 포함할 수 있다.
1.2. Table Directory heap-organized table의 경우, 이 디렉토리에는 rows가 이 블록에 저장된 테이블에 대한 메타데이터가 포함된다. table cluster에서 multiple tables이 동일한 블록에 rows를 저장할 수 있다.
1.3. Row Directory heap-organized table의 경우, 이 디렉토리는 블록의 데이터 부분에 있는 rows의 위치를 설명한다.
Row Format(Free Space/Row Data)
블록의 row data part에는 table rows or index key entries와 같은 실제 데이터가 포함된다. 모든 데이터 블록에 internal format이 있는 것처럼, 모든 row에는 database가 row에 있는 data를 추적할 수 있도록 하는 row format이 있다.
2.1. Row Header
Oracle은 row header를 사용하여 블록에 저장된 row piece를 관리한다.
2.2. Column Data
실제 데이터를 저장.
2.3. Rowid Format
Oracle은 rowid를 사용하여 row를 고유하게 식별한다.
참조:
Database Concepts
This chapter describes the nature of and relationships among logical storage structures. These structures are created and recognized by Oracle Database and are not known to the operating system.
docs.oracle.com